导言:寻找智能经济的逻辑起点
$$M \rightarrow C (MP + L) \dots P \dots C’ \rightarrow M’$$
在每一次重大的技术范式转移中,政治经济学的任务都是透过纷繁复杂的表象——无论是蒸汽机的轰鸣、电力的闪烁,还是如今数据中心里GPU的静默运算——去寻找那个最简单、最抽象、然而又包含了一切矛盾胚芽的“细胞形式”。对于马克思而言,工业资本主义的细胞是“商品”。而当我们站在以人工智能(AI)为核心的新经济大门口时,我们需要追问:什么是这个时代的商品形式?价值是如何在硅基半导体与碳基神经网络的交互中被创造、转移和积累的?
本报告旨在运用马克思政治经济学的批判体系,对当前正在爆发的AI经济进行一次结构性的重构。我们不满足于描述现象——如股市的波动、巨头的并购或政策的博弈——而是试图从逻辑起点出发,一步一步推导整个体系的演化路径。我们将看到,那些看似全新的概念,如Token、算力工厂(Compute Plant)、算力网(Compute Grid)以及所谓的“赛博封建主义”,实际上是资本逻辑在数字化、智能化条件下的必然展开。
我们将采纳一种冷峻的、历史唯物主义的视角。这不仅仅是关于技术的叙事,更是关于社会权力结构、价值形式以及人类文明在“丰裕”与“异化”之间抉择的宏大叙事。通过引入“社会必要智力时间”(Socially Necessary Intelligence Time, SNIT)这一核心范畴,我们将尝试解决AI经济中价值度量的难题,并揭示隐藏在“1.4万亿美元基建计划”1 背后的深刻经济动因。
第一篇 智能商品的微观结构与价值形式
第一章 智能商品的二重性:Token 的政治经济学分析
当我们剥去AI“神话”的外衣,就像马克思剥去商品的“拜物教”外衣一样,我们发现AI经济中最基本的单元并非是那个全知全能的模型,而是Token 。在现代大语言模型(LLM)的工业体系中,Token不仅是技术上的文本切片,更是智能商品的经济细胞。
1.1 Token 的使用价值:作为具体的智能服务
商品首先是一个外界的对象,一个靠自己的属性来满足人的某种需要的物。Token 的使用价值在于它承载了具体的、有用的智能服务。
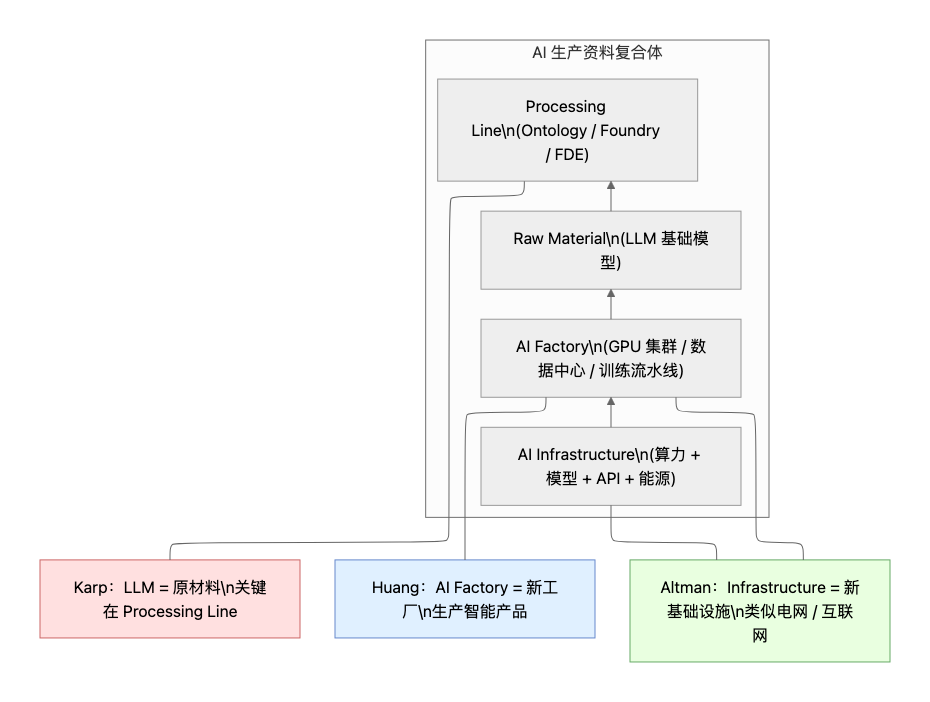
这种使用价值是千差万别的。一个Token可能是一段Python代码的关键字,帮助程序员节省了半小时的调试时间;它可能是一份法律文书中的关键条款,规避了巨大的商业风险;它也可能仅仅是一首生成诗歌中的韵脚,提供了审美愉悦。这种具体的、异质的使用价值,构成了Token的自然形态。在黄仁勋(Jensen Huang)的叙事中,AI工厂(AI Factories)之所以存在,就是为了生产这种“预测、推理和生成的原子单位”1 。
然而,Token 的使用价值具有不同于传统工业品的特征:
非竞争性(Non-rivalrous)的数字形态 :一旦生成,Token 本身可以被无限复制而边际成本趋近于零。生产过程的竞争性(Rivalrous Production) :尽管结果是数字的,但生成Token的过程——推理(Inference)——却需要独占物理算力(Compute)。GPU 的显存和计算单元在特定毫秒内只能服务于特定的请求。
这种使用价值与生产过程的矛盾,是理解AI经济“稀缺性”来源的第一把钥匙。
1.2 Token 的价值:凝结的抽象智力
如果把Token的使用价值抽去,它们还剩下什么属性呢?它们只剩下一种属性,即它们都是劳动产品。在AI经济中,这不再仅仅是人类的肌肉劳动,甚至不仅仅是人类的脑力劳动,而是一种人机混合的、社会化的抽象活动。我们将其定义为抽象智力劳动 。
在马克思的劳动价值论中,价值是凝结在商品中的无差别的人类劳动。在算力时代,我们需要对“劳动”的概念进行扩充。Token 的生产过程包含了两个不可分割的部分:
活劳动(Living Labor)的转化形式——Technikar :这是指甚至在模型训练之前和之中,人类科学家、算法工程师、数据标注员所投入的“精神劳动”(Geistige Arbeit)。他们是现代的技师(Technikar),将人类的普遍科学知识编码进神经网络的权重之中。死劳动(Dead Labor)的复活——Machine Compute :这是指固化在GPU、电力、数据中心设施中的过去劳动。在推理过程中,这些死劳动在电流的驱动下“复活”,参与到Token的生成中。
因此,Token 的价值实体是社会必要智力时间(Socially Necessary Intelligence Time, SNIT) 。
1.3 社会必要智力时间(SNIT)的界定
我们必须引入一个新的度量衡来解决价值量的问题。SNIT 是指在现有的社会正常的智力生产条件下,在社会平均的算力强度和算法熟练程度下,生产一个单位的智能产出所需要的劳动时间。
$$\text{SNIT} = \alpha(\text{Human Intellect}) + \beta(\text{Machine Compute})$$
$\alpha(\text{Human Intellect})$ :代表了人类智力投入的折算。这包括了基础模型的研发、对齐(Alignment)以及Prompt Engineering等人类认知活动。$\beta(\text{Machine Compute})$ :代表了机器算力的投入。这是可以被精确量化的物理过程,通常以 FLOPs(浮点运算次数)或 GPU-hours 为单位。
马克思关于复杂劳动是简单劳动的倍加的理论在这里依然适用。一个经过数万小时训练的博士生解决一个科学难题,和一个消耗了数万 GPU-hours 训练出的模型解决同一个难题,在价值论上是可以通约的。市场过程会将这两者还原为同质的 SNIT。
这解释了为什么AI经济具有强烈的通缩倾向 。随着摩尔定律(Moore’s Law)和黄氏定律(Jensen’s Law)的推动,$\beta$ 系数(单位算力的成本)急剧下降,导致生产单位Token所需的 SNIT 不断降低。如果价格不能随之下降,就会产生超额利润;如果价格随之下降,则需要通过指数级扩大消费量来维持价值总量的增长。
第二章 价值形式的演变:从算力本位到货币
价值不能孤立存在,它必须在交换中表现出来。Token 作为智能商品,必须寻找自己的价值表现形式。我们目睹了AI经济中价值形式的完整演化史,这正是马克思《资本论》第一章逻辑的历史重演。
2.1 简单的价值形式与扩大的价值形式
在AI发展的早期(例如2010年代),算力与智能的交换是偶然的、个别的。研究人员可能用具体的科研经费换取具体的云计算时长。这是简单的价值形式:
随着生态的成熟,各种智能服务开始相互交换。API 调用的Credits、数据集的授权费用、GPU的租赁价格形成了一个复杂的交换网络。这是扩大的价值形式。然而,这种杂乱的交换缺乏统一的尺度。
2.2 一般价值形式的出现:算力(Compute)作为一般等价物
随着交易的频繁,市场自发地从无数商品中分离出一种特殊的商品,用它来表现一切智能商品的价值。这种商品就是标准化的算力(Standardized Compute) 。
无论你是生成图片、编写代码还是分析基因序列,其背后的成本结构最终都可以还原为:占用了多少 A100/H100 GPU 的多少时间。于是,1个标准算力单位(C) ——例如 $10^{15}$ FLOPs 或者 1个标准 GPU-hour——开始扮演一般等价物的角色。
2.3 货币形式的完成:Token_Compute(算力币)
当标准算力单位固定地充当一般等价物时,它就取得了货币的地位。我们称之为Token_Compute(算力币) 。这不仅仅是一个理论假设,而是正在发生的现实:
物理锚定 :就像金本位时代的黄金一样,算力币锚定的是物理世界的做功能力(FLOPs)。它需要算力工厂(Compute Plant)作为“矿山”来开采(生产)。价值尺度 :OpenAI 的定价($X / 1M tokens)本质上是基于其后台算力成本的加成。所有智能服务的价格最终都在向算力成本回归。流通手段 :虽然目前还是以法币(美元)计价,但市场上已经出现了算力期货、GPU 租赁市场的代币化尝试。
我们将AI经济的货币体系概括为三个层级 1 :
底层:算力本位(Token_Compute, C) 。这是物理层,具有天然的通缩属性(技术进步使单位算力能产出更多智能)。中层:智力本位(Token_Intelligence, I) 。这是应用层,代表标准化的智力任务单(如“写一篇论文”)。由于供给无限增加,它具有通胀属性。上层:信用货币与资产(Fiat/RWA) 。这是金融层,通过稳定币等形式与算力本位挂钩。
价值形式 历史对应 AI经济表现 本质特征 简单形式 斧头=羊 数据=算力 偶然交换,无统一标准。 扩大形式 羊=茶/谷/金 API Credits体系 复杂的易货网络。 一般形式 牲畜/贝壳 H100 GPU-hour 物理算力成为价值参照系。 货币形式 黄金 Token_Compute (C) 标准化、可分割、可存储的算力通货。
第二篇 资本的生产过程:基础设施的政治经济学
第三章 货币转化为资本:AI 资本的总公式
在AI经济中,算力币(C)不仅作为流通手段,更作为资本投入流通。资本家(无论是Hyperscalers还是模型厂商)购买算力和数据,不是为了消费它们,而是为了生产出比原先价值更大的价值。
AI资本的总公式是:
$$M \rightarrow C (MP + L) \dots P \dots C’ \rightarrow M’$$
$M$ :预付的货币资本(数十亿美元的风险投资或企业留存收益)。$C$ :购买的生产要素。$MP$(生产资料) :包括不变资本(Constant Capital, $c$) ,即AI算力站(Compute Plant)、GPU集群、电力、冷却设施和数据(原材料)。$L$(劳动力) :包括可变资本(Variable Capital, $v$) ,即AI研究员、工程师(Technikar)以及数据标注员。$P$ :生产过程(训练 Training 和推理 Inference)。$C’$ :包含剩余价值的商品(训练好的模型或生成的Token流)。$M’$ :增殖了的资本。
这个公式揭示了AI经济的秘密:剩余价值不仅来源于对人类劳动力的剥削,更在于通过巨大的不变资本($c$)投入,利用机器算力倍增了智力产出的效率,从而攫取超额利润。
第四章 不变资本的巨构化:算力站(AI Compute Plant)的经济学
在AI资本的构成中,不变资本($c$)的占比正在经历爆炸式的增长。这集中体现在生产场所的变迁上:从传统的服务器机房(Data Center)进化为吉瓦级(Gigawatt-scale)的算力站(AI Compute Plant) 。
4.1 算力站的单位经济学分析
我们必须摒弃模糊的“数据中心”概念,采用更精确的工业视角。根据xAI的“Colossus”项目以及OpenAI/Microsoft的“Stargate”计划 1 ,我们推导出算力站的单位GW经济学模型。
建设一个1GW容量的AI算力站,其资本开支(CAPEX)结构如下:
IT设备资本(IT Capital) :主要是GPU(如NVIDIA H100/Blackwell)、服务器和高性能网络设备。按当前市场价,约占 250亿-300亿美元/GW 。设施资本(Facility Capital) :包括土地、建筑物、变电站、配电网络、液冷系统。约占 80亿-150亿美元/GW 。总计(Total Unit CAPEX) :330亿-450亿美元/GW 。
这意味着,Sam Altman 提出的1.4万亿美元、30GW的基建计划,并非“神话”或“疯话”,而是基于当前工业标准的理性推演 1 。这是一个极其资本密集的行业,其准入门槛之高,足以将绝大多数竞争者排除在外,导致资本的自然垄断 。
4.2 算力作为新型“电力”的假象与实质
人们常将AI算力比作电力。这种类比既深刻又具有误导性。
相似性 :两者都是通用技术(GPT),是其他所有生产活动的输入要素。差异性 :电力的产品是同质的能量,而算力的产品(Token)是异质的智能。更重要的是,电厂不生产最终消费品,而算力站通过生成Token,直接介入了内容、软件、决策等最终产品的生产。
因此,算力站不仅是能源的消耗者,它本身就是一座智能工厂(Intelligence Factory) 。黄仁勋将数据中心称为“AI Factories”是非常准确的政治经济学定义 1 :它输入原材料(数据+电力),输出商品(Token)。
第五章 可变资本的隐形化与技术人员(Technikar)的崛起
随着不变资本($c$)的膨胀,可变资本($v$)的形态也发生了剧变。
5.1 劳动力的两极分化
马克思曾预言机器大工业将导致工人的去技能化。在AI经济中,我们看到了劳动力的极端分化:
Technikar(技术创造者) :这是位于金字塔顶端的极少数人——顶级AI科学家、架构师。他们掌握着将人类知识转化为算法(Algorithm)和权重(Weights)的能力。他们的劳动具有极高的乘数效应,因此获得了类似资本的分配地位(巨额薪酬、股权)。他们是“总体工人”的脑器官。隐形的数据无产阶级(Data Proletariat) :这是分布在全球南方(Global South)或隐蔽在众包平台后的RLHF标注员。他们的劳动被碎片化、原子化,用于“对齐”模型的价值观。他们的劳动被深深地凝结在模型参数中,但其本身却在价值分配中被边缘化。
5.2 资本有机构成的急剧提高
资本有机构成($c/v$)的提高是资本主义发展的必然趋势。在AI行业,这一趋势达到了顶峰。一个价值1000亿美元的算力站,可能只需要几百名运维工程师和几千名远程标注员来维持。
这种极高的有机构成带来了一个经典的马克思主义矛盾:利润率趋向下降的规律 。因为只有活劳动($v$)才能创造新价值,而不变资本($c$)只是转移价值。为了维持利润率,AI资本必须:
无限扩大规模 :通过绝对量的增加来弥补利润率的下降。向外扩张 :将AI渗透到每一个人类活动领域,从写诗到制药,以剥削更多的社会剩余劳动。寻求租金 :从生产利润转向垄断租金(Cyber-Feudalism)。
第三篇 资本的流通过程:算力网与赛博封建主义
第六章 算力网(AI Compute Grid):流通的物质基础
资本如果不流通,就不是资本。算力站生产出的潜在智能(Compute Capacity),必须通过网络传输到用户端,才能转化为现实的商品(Inference)。连接生产与消费的,是算力网(AI Compute Grid) 。
6.1 算力网的构成
算力网不仅仅是互联网。它是专门为传输大模型权重、上下文数据和推理结果而优化的专用网络。它包括:
物理层 :光纤骨干网、跨海电缆、低延迟互联(InfiniBand/NVLink)。调度层 :负责在全球范围内的算力站之间调度任务,实现负载均衡(Load Balancing)。这类似于电网的调度中心。协议层 :定义了算力如何被请求、计费和交付的标准。
在我们的术语体系中,Hyperscalers(微软、谷歌、亚马逊)实际上已经建成了私有的全球算力网。而中国提出的“全国一体化算力网络”则是这一概念的国家基础设施版本 1 。
6.2 基础设施与路权(Road Rights)
马克思关注交通运输业作为生产过程在流通领域的继续。算力网就是AI时代的铁路和运河。谁掌握了算力网,谁就掌握了路权 。
基础设施型(Infrastructure Core) :如光纤运营商、塔商。他们是“修路者”,通常面临强监管和低回报率(类似公用事业)。平台型(Platform Protocol) :如Hyperscalers。他们不仅拥有路,还控制了“交通规则”(API协议、开发环境)。他们处于价值链的顶端。
第七章 赛博封建主义(Cyber-Feudalism):租金的政治经济学
当算力站和算力网的所有权高度集中时,资本主义的竞争逻辑开始向封建主义的租金逻辑退化。我们称之为赛博封建主义 。
7.1 领主、采邑与附庸
在赛博封建主义的结构中 1 :
领主(Lords) :拥有算力站、算力网和基础模型(Foundation Models)的巨头(如OpenAI+Microsoft, Google, Anthropic+Amazon)。采邑(Fiefs) :封闭的生态系统、专有的API接口、不互通的数据格式。领主将用户圈定在自己的领地内。附庸(Vassals) :依附于大模型的开发者、初创公司和传统企业。他们必须向领主缴纳“地租”(API调用费、云服务费),以换取在领地上耕作(开展业务)的权利。
7.2 技术性租金(Technological Rent)
不同于地租源于土地的自然稀缺,技术性租金源于人为制造的壁垒。
锁定效应(Lock-in) :一旦企业的业务流与某个模型的Prompt工程深度绑定,迁移成本极高。数据围栏(Data Enclosure) :领主利用用户数据反向训练模型,使得壁垒越来越高。
这种租金机制导致了价值分配的极端K型分化 1 :
上臂(Upper K) :拥有算力资本和平台路权的组织,享受超额租金和资产增值。下臂(Lower K) :普通企业和劳动者。他们不仅要承担AI转型的成本(失业、技能重塑),还要通过更高的电价(算力站抢电)、更高的通胀(芯片关税)来为AI基建买单。这就是所谓的“社会化成本,私有化收益”。
第四篇 资本的积累与国家的角色
第八章 创世纪任务(Genesis Mission):国家作为总资本家
面对AI资本的无限扩张和赛博封建主义的风险,国家机器被迫介入。美国政府发布的“Genesis Mission”行政令 1 ,标志着国家开始扮演**总资本家(General Capitalist)**的角色。
8.1 曼哈顿计划 2.0
这份由能源部(DOE)牵头的计划,其用语风格和组织架构明确指向了“曼哈顿计划”级别的国家动员。
目标 :建立一个“美国科学与安全平台”(American Science and Security Platform)。手段 :整合国家实验室的超算资源,建设政府自持的算力站和科研算力网。战略重心 :将AI作为底层引擎,去加速核能、生物、材料、半导体等六大关键领域的突破 1 。
8.2 国家资本与私人资本的博弈
这不仅仅是科技政策,而是所有权的博弈。Altman 呼吁建立“国家算力储备”,但拒绝政府为其私有数据中心兜底。这反映了私人资本试图将高风险、长周期的基础设施建设成本甩给国家,同时保留商业化利润的意图。
而“Genesis Mission”则表明,国家意图建立独立于Hyperscalers之外的主权算力网。这是一种双轨制:
商业轨道 :由私人资本主导,追求利润最大化,服务于消费互联网。主权轨道 :由国家资本主导,追求安全与科学霸权,服务于国家战略。
第九章 地缘政治经济学:算力主权与不平等交换
在世界市场范围内,算力成为了新的地缘政治货币。
9.1 算力帝国主义
拥有最高算力有机构成(Capital Organic Composition)的国家,能够生产出包含更高SNIT密度的智能商品,并以垄断价格出售给低算力国家。同时,它们通过控制算力站的建设标准和芯片供应链,锁定低算力国家在价值链底端的位置。
美国对高端GPU的出口管制,本质上是原始积累的封锁。它试图阻止竞争对手完成AI工业化所需的资本积累,从而维持自身的超额利润来源。
9.2 文明的岔路口:马斯克的时间线
埃隆·马斯克(Elon Musk)曾言:“我们同时面对着文明的衰落和不可思议的繁荣,这两条时间线交织在一起。” 1
用我们的政治经济学语言翻译,这就是资本积累的一般规律在AI时代的极端表现:
繁荣的时间线(上臂) :生产力(算力)的指数级增长带来了物质和智能的极大丰裕。衰落的时间线(下臂) :生产关系(私有制、赛博封建)的滞后导致了社会撕裂、制度失效和大多数人的相对贫困。
这两条线不是平行的,而是互为因果。极度的繁荣(技术突破)如果没有匹配的分配制度,必然加速文明的内部瓦解。
第五篇 危机与过渡:通向自由王国的路
第十章 利润率下降趋势与零边际成本危机
AI经济的终极矛盾在于:资本致力于通过自动化消灭劳动,但价值的唯一源泉恰恰是劳动。
随着AI无限逼近通用人工智能(AGI),Token的生产成本(SNIT)将无限趋近于零。
如果价格随价值下降:智能服务将变得像空气一样免费。利润消失,资本主义生产方式失去动力。
如果价格被人为维持(通过垄断):则形成阻碍生产力发展的桎梏,爆发深刻的实现危机。
第十一章 共产主义的幽灵:通过资本主义实现的乌托邦
如果我们在极高的生产力水平上打破私有制的限制,会发生什么?
我们面临一个历史性的反讽:AI资本主义正在为共产主义准备物质基础。
11.1 丰裕的物理条件
当算力站和算力网铺设完毕,当机器人能够自我复制,物质产品的稀缺性将被从技术上消灭。按需分配(To each according to his needs)不再是道德理想,而是工程上的可行方案。
11.2 分配机制的革命:从工资到全民算力(UBC)
在劳动不再是生产的主要要素时,工资体系必将崩溃。取而代之的分配形式必须建立在对算力这一公共基础设施的所有权之上。
全民基本算力(Universal Basic Compute, UBC) :每个公民天生拥有一定份额的算力网使用权。主权算力分红 :国家算力站的收益直接转化为国民红利。
11.3 智力本位的通胀与解放
在我们的货币模型中,算力币(C)因技术进步而通缩,意味着人类对物理世界的掌控力增强。而智力币(I)因供给无限而通胀,这意味着“智力劳动”不再是谋生的手段,而回归为人的自由活动。
马克思所说的“自由王国”——在那里面,劳动已经不仅仅是谋生的手段,而且本身成了生活的第一需要——在AI时代显现出具象的轮廓。
结论:以算力重构政治经济学
通过将马克思的政治经济学体系引入AI时代,我们完成了一次理论的重构:
商品论 :确立了Token作为智能商品的地位,定义了社会必要智力时间(SNIT)作为价值实体。货币论 :推导了算力本位(Token_Compute)作为数字时代一般等价物的必然性。生产论 :揭示了算力站作为巨型不变资本的积累逻辑,以及其对劳动力的排斥效应。流通论 :分析了算力网作为基础设施的权力属性,以及赛博封建主义的租金机制。国家论 :阐明了国家作为总资本家介入基建(Genesis Mission)的历史动因。
我们得出的结论是:AI不只是一次技术革命,它是资本主义生产方式的最高阶段,也是它的最后阶段。它将生产力的社会化推向了极致(全球算力网),从而使生产资料的私人占有变得越来越不兼容。K型分化的加剧、赛博封建的兴起、地缘政治的紧张,都是这一根本矛盾的阵痛。
人类文明的未来,取决于我们能否驾驭这股力量——不是作为资本增殖的工具,而是作为全人类解放的物质基础。这不仅是经济学的任务,更是政治学的使命。
附录:关键数据与术语表
表1:AI 算力站的单位经济学(Unit Economics of AI Compute Plant)
成本项目 估算成本 (每 GW) 备注 IT 资本 (GPUs/Servers) $250亿 – $300亿 基于 NVIDIA H100/Blackwell 价格推算 1 设施资本 (Facility/Power) $80亿 – $150亿 含土地、变电站、液冷系统 总计 (Total CAPEX) $330亿 – $450亿 对应 OpenAI $1.4T/30GW 计划的理性区间
表2:历史基础设施与 AI 基建的对照
维度 电力时代 (1920s) AI 时代 (2020s) 核心单元 kWh (千瓦时) Token / FLOPs 生产场所 发电厂 (Power Plant) 算力站 (Compute Plant) 1 流通网络 电网 (Power Grid) 算力网 (Compute Grid) 关键人物 Insull (电网大亨) Altman / Hyperscalers 经济特征 自然垄断,后转为公用事业 赛博封建,正处于垄断形成期 国家角色 监管法案 (PUHCA) 创世纪任务 (Genesis Mission)
表3:术语对照表
Token_Compute (C) : 算力本位币,物理层价值尺度 (1C = $10^{15}$ FLOPs)。Token_Intelligence (I) : 智力本位币,应用层任务单位,具有通胀属性。SNIT : 社会必要智力时间,价值实体。Technikar : 技术创造者,AI时代的高级劳动者。Genesis Mission : 美国能源部牵头的国家AI科研平台计划。